| [ Team LiB ] |
|
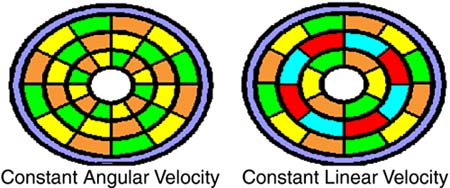
Hard DisksPeople who think they know such things often liken a computer's hard disk to a filing cabinet. Such folk really don't know much about hard disksor the way real people store information. A hard disk is more like the desk and office of a writer, who in his few lucid moments between delirium tremens and alcoholic stupor crafts work of unparalleled insight and beauty from the scribbled notes, torn-out newspaper stories, yellowing magazines, and broken-back books stacked everywhere in piles that defy both organizational sense and the law of gravity. (Think Poe with the benefit of modern chemistry.) Your computer's hard disk only looks organized, an illusion as compelling as your own feelings of prowess and courage that arise after you've drunk a meal with your friend, the alcoholic writer. In reality, it's much more like the pack rat's stash the writer calls an office, with uncountable snippets of thoughts, beat-up old photographs, and little bright shiny things all heaped together, some worth keeping, some that should have been tossed long ago, and a trash bag full of things that were thrown away but haven't yet been carried out. Your hard disk holds everything you work with on your computer as well as a surprising amount of stuff that you'll never use again. It is your computer's long-term memory, but on the disk, the information is confounded into pieces much like a messy desk or your own mind. Unlike your mind or mess, however, the disk has an organizing aid, the operating system. All the neatly arranged files you store on your disk owe their existence to the operating system. Dig deep into your hard disk and you'll see it's nothing but a receptacleor a giant collection of receptaclesfor storing blocks of information. The disk's job is simply to put the information into the receptacles, preserve it, and retrieve it in the off-chance that you need it again. As with everything else, the hard work of the hard disk is in the details. The hard disk is actually a combination device, a chimera that's part electronic and part mechanical. Electrically, the hard disk performs the noble function of turning evanescent pulses of electronic digital data into more permanent magnetic fields. As with other magnetic recording devicesfrom cassette recorders to floppy disksthe hard disk accomplishes its end using an electromagnet, its read/write head, to align the polarities of magnetic particles on the hard disk itself. Other electronics in the hard disk system control the mechanical half of the drive and help it properly arrange the magnetic storage and locate the information that is stored on the disk. HistoryBecause of their ability to give nearly random access to data, magnetic disk drives have been part of computing since long before there were personal computers. The first drives suffered from the demands of data processing, however, and quickly wore out. Their heads ground against their disks, leaving dust where data had been. For fast access, some lined dozens of heads along the radius of the disk, each sweeping its own dedicated range of disk and data. Such designs had fast access speeds, dependent only on the speed of the spin of the disk (which is still an issue, even today), and minimal maintenance worries because they had a minimum of moving parts. But the size of the heads and the cost of arraying a raft of them meant such drives were inevitably expensive. Though not a major problem with mainframe computers priced in the millions, pricing a computer with such a drive would put the computer within the budgets solely of those with personal Space Shuttles in their garages. The breakthrough came at IBM's Hursley Labs near Winchester in England. Researchers there put a single head to work scanning across the disk to get at every square inch (England had not yet gone metric) of its surface. Their breakthrough, however, totally eliminated the wear of head against disk and was destined to set the standard for computer storage for more than three decades. By floatingactually flyingthe read/write head on a cushion of air, the head never touched the disk and never had a chance to wear it down. Moreover, the essentially friction-free design allowed the head to move rapidly between positions above the disk. This original design had two sections: a "fixed" drive that kept its disk permanently inside and a removable section that could be dismounted for file exchange or archiving. Each held 30MB on a platter about 14 inches across. During development, designers called the drive a 30/30 to reflect its two storage sections. In that Remington used the same designation for its most famous repeating riflethe gun that won the Westthis kind of drive became known as a Winchester disk drive. The name Winchester first referred to the specific drive model. Eventually it was generalized to any hard disk. In the computer industry, however, the term was reserved for drives that used that same head design as the original Winchester. New disk drivesincluding all those now in computersdo not use the Winchester head design. Besides Winchester, you may also hear other outdated terms for what we today call a hard disk. Many folks at IBM still refer to them as fixed disks. When computer people really want to confound you, they sometimes use another IBM term from the dark ages of computing, DASD, which stands for Direct Access Storage Device. No matter the name, however, today all hard disks are essentially the same in principle, technology, and operation. MechanismThe mechanism of the typical hard disk is actually rather simple, comprising fewer moving parts than such exotic devices as the electric razor and pencil sharpener. The basic elements of the system include a stack of one or more plattersthe actual hard disks themselves. Each of these platters serves as a substrate upon which is laid a magnetic medium in which data can be recorded. Together the platters rotate as a unit on a shaft, called the spindle. Typically the shaft connects directly to a spindle motor that spins the entire assembly. RotationHard disks almost invariably spin at a single, constant rate measured in revolutions per minute (RPM). This speed does not change while the disk is in operation, although some disks may stop to conserve power. Storing information using this constant spin is technically termed constant angular velocity recording. This technology sets the speed of the disk's spin at a constant rate so that, in any given period over any given track, the drive's read/write head hangs over the same-length arc (measured in degrees) of the disk. The actual length of the arc, measured linearly (in inches or centimeters) varies depending on the radial position of the head. Although the tiny arc made by each recorded bit has the same length when measured angularly (that is, in degrees), when the head is farther from the center of the disk, the bit-arcs are longer when measured linearly (that is, in inches or millimeters). Despite, or because of, the greater length of each bit toward the outer edge of the disk, each spin stores the same number of bits and the same amount of information. Each spin at the outer edge of the disk stores exactly the same number of bits as those at the inner edge. Constant angular velocity equipment is easy to build because the disk spins at a constant number of RPM. Old vinyl phonograph records are the best example of constant angular velocity recordingthe black platters spun at an invariant 33 1/3, 45, or 78 RPM. Nearly all hard disks and all ISO standard magneto-optical drives use constant angular velocity recording. A more efficient technology, called constant linear velocity recording, alters the spin speed of the disk depending on how near the center tracks the read/write head lies, so that in any given period, the same length of track passes below the head. When the head is near the outer edge of the disk, where the circumference is greater, the slower spin allows more bits and data to be packed into each spin. Using this technology, a given-size disk can hold more information. Constant linear velocity recording is ill-suited to hard disks. For the disk platter to be properly read or written, it must be spinning at the proper rate. Hard disk heads regularly bounce from the outer tracks to the inner tracks as your software request them to read or write data. Slowing or speeding up the platter to the proper speed would require a lengthy wait, perhaps seconds because of inertia, which would shoot the average access time of the drive through the roof. For this reason, constant linear velocity recording is used for high-capacity media that don't depend so much on quick random access. The most familiar is the Compact Disc, which sacrifices instant access for sufficient space to store your favorite symphony. Figure 17.1 illustrates the on-disk difference between the two methods of recording. The sector length varies in constant angular velocity but remains constant using constant linear velocity. The number of sectors is the same for each track in constant angular velocity recording but varies with constant linear velocity recording. Figure 17.1. Comparison of constant angular and line velocity recording methods.
Modern hard disks compromise between constant angular velocity and constant linear velocity recording. Although they maintain a constant rotation rate, they alter the timing of individual bits depending on how far from the center of the disk they are written. By shortening the duration of the bits (measured in microseconds) over longer tracks, the drive can maintain a constant linear length (again, measured in inches or whatever) for each bit. This compromise technique underlies multiple zone recording technology, which we will more fully discuss later. SpeedThe first disk drives (back in the era of the original IBM Winchester) used synchronous motors. That is, the motor was designed to lock its rotation rate to the frequency of the AC power line supplying the disk drive. As a result, most motors of early hard disk drives spun the disk at the same rate as the power line frequency, 3600 revolutions per minute, which equals the 60 cycles per second of commercial power in the United States. Synchronous motors are typically big, heavy, and expensive. They also run on normal line voltage117 volts ACwhich is not desirable to have floating around inside computer equipment where a couple of errant volts can cause a system crash. As hard disks were miniaturized, disk-makers adopted a new technologythe servo-controlled DC motorthat eliminated these problems. A servo-controlled motor uses feedback to maintain a constant and accurate rotation rate. That is, a sensor in the disk drive constantly monitors how fast the drive spins and adjusts the spin rate should the disk vary from its design specifications. Because servo motor technology does not depend on the power-line frequency, manufacturers are free to use any rotation rate they want for drives that use it. Early hard disks with servo motors stuck with the standard 3600 RPM spin to match their signal interfaces designed around that rotation rate. Once interface standards shifted from the device level to the system level, however, matching rotation speed to data rate became irrelevant. With system-level interfaces, the raw data is already separated, deserialized, and buffered on the drive itself. The data speeds inside the drive are entirely independent from those outside. With this design, engineers have a strong incentive for increasing the spin rate of the disk platter: The faster the drive rotates, the shorter the time that passes between the scan of any two points on the surface of the disk. A faster spinning platter makes a faster responding drive and one that can transfer information more quickly. With the design freedom afforded by modern disk interfaces, disk designers can choose any spin speed without worrying about signal compatibility. As a result, the highest performing hard disks have spin rates substantially higher than the old standardsome rotate as quickly as 10,000 or 15,000 RPM. Note that disk rotation speed cannot be increased indefinitely. Centrifugal force tends to tear apart anything that spins at high rates, and hard disks are no exception. Disk designers must balance achieving better performance with the self-destructive tendencies of rapidly spinning mechanisms. Moreover, overhead in computer disk systems tends to overwhelm the speed increases won by quickening disk spin. Raising speed results in diminishing returns. Today, most of the spins of hard disks fit a three-tier hierarchy. The slowest, turning 4200 RPM, are used only in notebook computers. Disks running at 5400 RPM are general-purpose consumer drives, although a few newer "high-performance" drives for notebook machines now reach this speed. Faster drives are used in network servers and high-performance workstations. This high-performance category itself has three speed levels: 7500, 10,000, and 15,000 RPM. LatencyDespite the quick and constant rotation rate of a hard disk, it cannot deliver information instantly on request. There's always a slight delay that's called latency. This term describes how long after a command to read from or write to a hard disk the disk rotates to the proper angular position to locate the specific data needed. For example, if a program requests a byte from a hard disk and that byte has just passed under the read/write head, the disk must spin one full turn before that byte can be read from the disk and sent to the program. If read and write requests occur at essentially random times in regard to the spin of the disk (as they do), on the average the disk has to make half a spin before the read/write head is properly positioned to read or write the required data. Normal latency at 3600 RPM means that the quickest you can expect your hard diskon the averageto find the information you want is 8.33 milliseconds. For a computer that operates with nanosecond timing, that's a long wait, indeed. The newer hard disks with higher spin speeds cut latency. The relationship between rotation and latency is linear, so each percentage increase in spin pushes down latency by the same factor. A modern drive with a 5400 RPM spin achieves a latency of 5.56 milliseconds. Table 17.1 lists the latency of disks based on rotation rate. Standby ModeDuring operation, the platters in a hard disk are constantly spinning because starting and stopping even the small mass of a two-inch drive causes an unacceptable delay in retrieving or archiving your data. This constant spin ensures that your data will be accessible within the milliseconds of the latency period. In some applications, particularly notebook computers, the constantly spinning hard disk takes a toll. Keeping the disk rotating means constant consumption of power by the spindle motor, which means shorter battery life. Consequently, most hard disks are designed to be able to cease spinning when they are not needed. Typically, the support electronics in the host computer determine when the disk should stop spinning. Current versions of Windows make this feature optional (you'll find the controls in the Power Option section of Control Panel). When the feature is activated (as it is by default in most notebook computers), it means that if you don't access the hard disk for a while, the computer assumes you've fallen asleep, died, or had your body occupied by aliens and won't be needing to use the disk for some time. When you do send out a command to read or write the disk, you then will have to wait while it spins back up to speedpossibly as long as several seconds. Subsequent accesses then occur at high hard disk speeds until the drive thinks you've died again and shuts itself down. The powering down of the drive increases the latency from milliseconds to seconds. It can be a big penalty. Consequently, most notebook computers allow you to adjust the standby delay. The longer the delay, the more likely your drive will be spinning when you want to access itand the quicker your computer's battery will discharge. If you work within one application, a short delay can keep your computer running longer on battery power. If you shift between applications when using Windows or save your work often, you might as well specify a long delay because your disk will be spinning most of the time, anyway. Note, too, that programs with auto-saving defeat the purpose of your hard disk's standby mode, particularly when you set the auto-save delay to a short period. For optimum battery life, you'll want to switch off auto-savingif you have sufficient faith in your computer. Data-Transfer RateThe speed of the spin of a hard disk also influences how quickly data can be continuously read from a drive. At a given storage density (which disk designers try to make as high as possible to pack as much information in as small a package as possible), the quicker a disk spins, and the faster information can be read from it. As spin rates increase, more bits on the surface of the disk pass beneath the read/write head in a given period. This increase directly translates into a faster flow of datamore bits per second. The speed at which information is moved from the disk to its control electronics (or its computer host) is termed the data-transfer rate of the drive. Data-transfer rate is measured in megabits per second, megahertz (typically these two take the same numeric value), or megabytes per second (one-eighth the megabit per second rate). Higher is better. The data-transfer rates quoted for most hard disks are computed values rather than the speeds you should expect in using a hard disk drive in the real world. A number of factors drive down the actual rate at which information can be transferred from a disk drive. The measure of the actual amount of useful information that moves between a disk drive and your computer is called the throughput. It is always lowersubstantially lowerthan the disk's data-transfer rate. The actual throughput achieved by a drive system varies with where the measurement is made because each step along the way imposes overhead. The throughput between your drive and controller is higher than between drive and memory. And the actual throughput to your programswhich must be managed by your operating systemis slower still. Throughput to your operating system on the order of a few hundred kilobytes per second is not unusual for hard disk drives that have quoted transfer rates in excess of 10 or 20 megabytes per second. Read/Write HeadsBesides the platters, the only other moving part in most hard disk drives is the head system. In nearly all drives, one read/write head is associated with each side of each platter and flies just above or below its surface. Each of these read/write heads is flexibly connected to a more rigid arm, which supports the flying assembly. Usually several of these arms are linked together to form a single moving (usually pivoting) unit. Physical DesignThe head is loosely connected to the actuator so that it can minutely rise or fall. When the hard disk drive is turned off or in sleep mode so that its platters are not spinning, the head rests lightly against them by a slight spring force. The physical design of the head makes it into an airfoil much like an airplane wing. As the platters spin, they drag the air in contact with them along for the ride. The moving air creates a slight breeze, which, like the air whisking past the airplane wing, generates lift on the hard disk head's airfoil. The head rises, flying a few millionths of an inch above the spinning surface of the platter. The height at which the read/write head of a hard disk flies is one factor in determining the ultimate storage capacity of the drive. Magnetic fields spread out with distance, so the farther the head is from the disk, the larger the apparent size of the field that's generated by a flux transition on the disk. Moving the head closer shrinks the apparent size of the flux transitions, allowing them to be packed closely together on the disk surface and increasing the capacity of the disk. The typical first-generation hard disk head flew about 10 to 12 micro-inches (millionths of an inch) above the surface of the platter. Modern disk drive heads fly closer, five or fewer micro-inches. These lower heights are possible thanks to smoother platters and smooth thin-film media. Electrical DesignFlying is a means to an end, not the ultimate purpose of the read/write head. The real job of the head is to create or detect the magnetic pulses on the disk platter that correspond to the data you store there. Modern hard disks use one of two basic designs to accomplish this design purpose: inductive or magneto-resistive. Inductive Read/Write HeadsAn inductive read/write head is nothing more than a miniature electromagnet akin those of childhood experimentation. Wrap a long length of wire around and around a nail, connect the two ends of the wire to the positive and negative terminals of a battery, and the nail becomes a magnet. The electricity flowing through the wire induces a magnetic field in the nail. In the inductive read/write head, the wire is called the coil and the part that acts as the nail is the core. The principle is the same. The disk drive electronics send a current through the read/write head coil, which induces a magnetic field in the core. The magnetic field alters the orientation of the magnetic particles on the nearby platter. The read process simply reverses the relationship. The magnetic fields of the particles on the platter slightly magnetize the core, which, in turn, induces a small voltage in the coil. The disk drive electronics detect the small voltage fluctuations in the coil and interpret them as data. The physical design of the core allows the focusing of the head's read and write capabilities into a small area. Instead of a long, thin nail, the core is folded so that its two poles (ends) are not quite touching, separated by a thin gap. This design concentrates the magnetic field into the tiny gap. The first practical read/write heads, those in vintage tape recorders, had nothing more than air in the gap. Basic disk drive read/write heads fill the gap with a nonmagnetic metal. Such designs are termed metal-in-gap heads. Modern read/write heads replace the coil of wire with a thin layer of copper deposited in coil form as a film. Called thin-film heads, their technology allows for finer, lower-mass coils that are easier and less expensive to fabricate. Magneto-Resistive HeadsThe latest trend in head design is magneto-resistive read/write heads. These heads work on an entirely different physical principle from inductive heads. They measure the change in electrical resistance that a magnetic field causes in some materials. The disk drive electronics send a small, constant current through the magneto-resistive material (usually an alloy of iron and nickel) and measure the change in voltage across the headas the resistance of the head goes up, the voltage goes down. The change is minuscule but easily detectable by modern precision electronics. The magneto-resistive action is one-way. It can be used only to detect changes in magnetic fields. It cannot create the fields. In other words, the magneto-resistive principle works only for read operations. Consequently, disk drives with magneto-resistive heads actually have combination headsa magneto-resistive read head combined with an inductive write head. Dividing the functions of a read/write head into separate elements allows each to be tailored to best operation. The magneto-resistive design allows for higher frequency operation, which equates to greater storage densities and operating speeds. Write PrecompensationConstant angular velocity recording has another drawback: The shorter sectors closer to the spindle require data to be packed into them more tightly, squeezing the magnetic flux reversals in the recording medium ever closer together. The ability of many magnetic media to hold flux transitions falls off as the transitions are packed more tightlypinched together, they produce a feebler field and induce a lower current in the read/write head. One way of dealing with this problem is to write on the disk with a stronger magnetic field as the sectors get closer to the spindle. By increasing the current in the read/write head when it writes nearer the center of the disk, the on-disk flux transitions can be made stronger. They can then induce stronger currents in the read/write head when that area of the disk is read. This process is called write precompensation because the increased writing current compensates for the fall off in disk responses nearer its center at a place logically before the information is stored on the disk. The electronics of modern hard disk drives automatically make the necessary compensation. Partial Response Maximum LikelihoodAlthough group-coding techniques have served well through the evolution of the computer hard disk, another technique called Partial Response Maximum Likelihood (PRML) technology works in the opposite direction. Instead of modifying the dataessentially expanding it to make it work better with existing hardwarePRML modifies the read electronics of the disk drive so they can better sort through densely recorded data. IBM first introduced PRML electronics in 1990, and the technology found its way into computer hard disk drives a few years later. PRML works only during reading the disk. Its specific goal is to compensate for intersymbol interference, a kind of distortion that appears when a drive packs data densely. As the read/write head scans the disk, it produces an analog signal. Conventional disk read electronics detect the peaks of the analog pulses and translate them into digital bits. At high bit-rates, which occur when flux transitions are packed densely and the disk spins rapidly, the peaks can blur together. The electronics can readily mistake two bits for one or make similar errors. PRML read electronics can better sort through the analog signals and more reliably translate the signals into data. The first step in the PRML process is to filter the signal from the read/write head using digital techniques, shaping it with a partial response characteristic by altering its frequency response and timing characteristics. Using digital processing, the PRML system then detects where signals from flux transitions are most likely to occur. The PRML system uses a sequence-detection algorithm that accurately sorts through the data. The chief advantage of PRML is that it ensures data integrity with high bit densities and faster data rates between head and electronics. PRML does not require special coding during recording. In fact, one of its advantages is that it sidesteps the increase in bit-count that arises with group-coding techniques. Because fewer bits must be written to disk, PRML allows more data to fit on a given disk. Because PRML allows higher disk densities, it can increase the read rate of a disk without altering its mechanical rate of rotation. Head ActuatorsEach read/write head scans the hard disk for information. Were the head nothing more than that, fixed in position as is the head of a tape recorder, it would only be able to read a narrow section of the disk. The head and the entire assembly to which it is attached must be able to move in order to take advantage of all the recordable area on the hard disk. The mechanism that moves the head assembly is called the head actuator. Usually the head assembly is pivoted and is swung across the disk by a special head actuator solenoid or motor. The first head actuators were open loop. That is, the actuator moved the head to a preset position and hoped it was right. Modern actuators are closed loop. They move the head, check its position over the disk (by reading magnetically coded identification from the disk), and readjust the position until they get it right. Closed-loop actuators are more accurate and quicker. The closed-loop system gets a constant stream of information regarding the head position from the disk, so it always knows exactly where the head is. The system determines the location of the head by constantly reading from a special, dedicated side of one platterthe servo surfacethat stores a special magnetic pattern that allows the drive mechanism to identify each storage location on the disk. Some more recent magnetic hard disks put the servo information on the same recording surface as the stored data. This combined data-and-servo system is called embedded servo technology. The most common of the closed-loop actuator systems uses a voice coil mechanism that operates like the voice coil in a loudspeaker and is therefore called a servo-voice coil actuator. In this design, a magnetic field is generated in a coil of wire wrapped around part of the actuator (making it a solenoid) by the controlling electronics, and this field pulls the head mechanism against the force of a spring. By varying the current in the coil, the head mechanism is drawn farther from its anchoring spring, and the head moves across the disk. The voice coil mechanism connects directly to a pivoting arm, which also supports the read/write head above the platter. The varying force of the voice coil swings the head in an arc across the platter surface. Landing ZoneHard disks are most vulnerable to head crash damage when they are turned off. As soon as you flick the off switch on your computer, the platters of its hard disk must stop spinning, and the airflow that keeps the heads flying stops. Generally, the airflow decreases gradually, and the head slowly progresses downward, eventually landing like an airplane on the disk media. In truth, however, any head landing is more of a controlled crash and holds the potential for disk damage. Consequently, most hard diskseven those with thin-film mediahave a dedicated landing zone reserved in their media in which no data can be recorded. This landing zone is usually at the inner edge of the actual data storage area. Park-and-LockUsually a software command is necessary to bring the head to the landing zone and hold it there while the disk spins down. This process is called head parking. The first hard disks had no special provisions for parking their heads and required a specific software command to move their heads to the landing zone. All modern hard disks are designed so that whenever their power is switched off, the head automatically retracts to the landing zone before the disk spins down. Such drives are said to have automatic head parking. In addition, the most modern drives latch their heads in the landing zone after power is removed. The latch prevents an impact or other shock to the system from jarring the head out of the landing zone and, in the process, bouncing it across the vulnerable medium. This feature is generally termed automatic park-and-lock. All drives now incorporate it. Thermal CompensationAll materials expand and contract as temperatures change, and the metals used in constructing hard disk drives are no exception. As a drive operates, it generates heat from the motors that spin its platters, the actuator that moves the heads, and the electronics that control its operation. This heat causes the various components of the drive to expand slightly, changing its dimensions slightly but measurably. Because of the miniaturization of modern hard disks that packs thousands of tracks in an inch, even this slight thermal expansion can alter the geometry of the drive sufficiently that heads and tracks can move from their expected positions. To compensate for such changes, most hard disk drives periodically perform a thermal calibration, or T-cal. The disk moves its heads to read special calibration tracks to reestablish a proper reference for head positioning. Drive manufacturers developed their own algorithms for determining when their drives would perform thermal calibration (for example, at fixed intervals or upon the occurrence of seek errors). In general, the thermal compensation takes priority over normal read operations and sometimes imposes a delay when you request data. The delay can amount to several dozen milliseconds because the drive's heads must move to the calibration tracks before fulfilling any data requests. To avoid the delays imposed by thermal calibration, many high-performance drives have the ability to delay the calibration until the completion of a read operation to avoid the interrupt of the delivery of prolonged sequential data streams, such as those that might occur in playing back a video clip. Most drives calibrate all heads simultaneously, which results in the drive being unavailable for reading or writing data for the milliseconds required by the recalibration. A few drives can now recalibrate heads individually, allowing the other heads to retrieve data at the same time. MediumThe disk spinning inside the hard disk drive is central to the drivein more ways than one. The diameter of this platter determines how physically large a drive mechanism must be. In fact, most hard disk drives are measured by the size of their platters. When the computer first burst upon the scene, makers of hard disks were making valiant attempts at hard disk platter miniaturization, moving from those eight inches in diameter (so-called eight-inch disks) to 5.25-inch platters. Today the trend is toward ever-smaller platters. Most large-capacity drives bound for desktop computer systems now use 3.5-inch platters. Those meant for computers in which weight and size must be minimized (which means, of course, notebook and smaller computers) have platters measuring 2.5, 1.8, or 1.3 inches (currently the smallest) in diameter. (See Chapter 32, "Cases," for form-factor details.) To increase storage capacity in conventional magnetic hard disk storage systems, both sides of a platter are used for storing information, each surface with its own read/write head. (One head is on the bottom, where it must fly below the platter.) In addition, manufacturers often put several platters on a single spindle, making a taller package with the same diameter as a single platter. The number of platters inside a hard disk also influences the speed at which data stored on the hard disk can be found. The more platters a given disk drive uses, the greater the probability that one of the heads associated with one of those platters will be above the byte that's being searched for. Consequently, the time to find information is reduced. SubstratesThe platters of a conventional magnetic hard disk are precisely machined to an extremely fine tolerance, measured in micro-inches. They have to beremember, the read/write head flies just a few micro-inches above each platter. If the disk juts up, the result is akin to a DC-10 encountering Pike's Peaka crash that's good for neither airplane nor hard disk. Consequently, disk-makers try to ensure that platters are as flat and smooth as possible. The most common substrate material is aluminum, which has several virtues: It's easy to machine to a relatively smooth surface. It's generally inert, so it won't react with the material covering it. It's nonmagnetic, so it won't affect the recording process. It has been used for a long while (since the first disk drives) and is consequently a familiar material. And above all, it's cheap. A newer alternative is commonly called the glass platter, although the actual material used can range from ordinary window glass to advanced ceramic compounds akin to Space Shuttle skin. Glass platters excel at exactly the same qualities as do aluminum platters, only more so. They can be smooth and allow read/write heads to fly lower. They are also less reactive than aluminum and, with the right choice of material, can be lighter. Areal DensityThe smoothness of the substrate affects how tightly information can be packed on the surface of a platter. The term used to describe this characteristic is areal densitythat is, the amount of data that can be packed onto a given area of the platter surface. The most common unit for measuring areal density is megabits per square inch. The higher the areal density, the more information that can be stored on a single platter. Smaller hard disks require greater areal densities to achieve the same capacities as larger units. Areal density is generally measured in megabytes per square inch of disk surface, and current products achieve values on the order of 500 to 1000 megabits per square inch. A number of factors influence the areal density that can be achieved by a given hard disk drive. The key factor is the size of the magnetic domain that encodes each bit of data, which is controlled in turn by several factors. These include the height at which the read/write head flies and the particle (grain) size of the medium. Manufacturers make read/write heads smaller to generate smaller fields and fly them as closely to the platter as possible without risking the head running into the jagged peaks of surface roughness. The smoothness of the medium determines the lowest possible flying heighta head can fly closer to a smoother surface. The size of magnetic domains on a disk is also limited by the size of the magnetic particles themselves. A domain cannot be smaller than the particle that stores it. At one time, ball mills ground a magnetic oxide medium until the particle size was small enough for the desired application. Platters were coated with a slurry of the resulting magnetic material. Modern magnetic materials minimize grain size by electroplating the platters. MediaThe first magnetic medium used in hard disks was made from the same materials used in conventional audio recording tapesferric or ferrous oxide compounds (essentially fine grains of rather exotic rust). As with recording tape, the oxide particles are milled in a mixture of other compounds, including a glue-like binder and often a lubricant. The binder also serves to isolate individual oxide particles from one another. This mud-like mixture is then coated onto the platters. But this coating is rather rough, too rough for today's high-capacity, small-size hard disks. Moreover, it is soft and prone to damage should the read/write head touch it, resulting in a head crash that may render part of the disk unusable. As a result, although once an important technology, oxide media have been abandoned by drive-makers. In all current hard disk drives, drive-makers have replaced oxide coatings with thin-film magnetic media. As the name implies, a thin-film disk has a microscopically skinny layer of a pure metal, or mixture of metals, mechanically bound to its surface. These thin-films can be applied either by plating the platter, much the same way chrome is applied to automobile bumpers, or by sputtering, a form of vapor-plating in which metal is ejected off a hot electrode in a vacuum and electrically attracted to the disk platter. The very thinness of thin-film media allows higher areal densities because the magnetic field has less thickness in which to spread out. Because the thin-film surface is smoother, it allows heads to fly closer. Thin-film media also have higher coercivities, which allow smaller areas to produce the strong magnetic pulses needed for error-free reading of the data on the disk. One reason that thin film can be so thin and support high areal densities is that, as with chrome-plated automobile bumpers and faucets, plated and sputtered media require no binders to hold their magnetic layers in place. Moreover, as with chrome plating, the thin films on hard disk platters are genuinely hard, many times tougher than oxide coatings. That makes them less susceptible to most forms of head crashingthe head merely bounces off the thin-film platter just as it would your car's bumpers. ContaminationContaminants such as dust and air pollution particles stuck to the media surface can cause problems. With older oxide media drives, contaminants could result in a head crash. With plated media, contaminants aren't as likely to cause damage, but they can interfere with the proper read/write operation of the drive. To help guard against contamination of the platter surface with dust, hair, and other floating gunk, most hard disks keep all their vulnerable parts in a protective chamber. In fact, this need to avoid contamination is why nearly all computer hard disks use nonremovable media, sealed out of harm's way. The disk chamber is not completely airtight. Usually a small vent is designed into the system to allow the air pressure inside the disk drive to adjust to changes in environmental air pressure. Although this air exchange is minimal, a filter in this vent system traps particles before they can enter the drive. Microscopic pollutants, such as corrosive molecules in the air, can seep through the filter, however, potentially damaging the disk surface. Although the influx of such pollutants is smallthe hard disk vent does not foster airflow, only pressure equalizationit is best not to operate a hard disk in a polluted environment. You wouldn't want to be there to use it, anyhow. GeometryThe geometry of a hard disk expresses the physical arrangement on the platters inside the drive. Today it is an issue for engineers only because the logical block addressing used by all new hard disk drives effectively hides the drive geometry from you and your operating system. As long as a drive has all the blocks it advertises, they could be laid out like a Jackson Pollock painting, and your operating system wouldn't know the difference. If you accidentally enter the netherworld of your computer's BIOS setup and jog your hard disk away from automatic configuration, you likely will be confronted with a disk parameter table that requests you enter the number of heads, cylinders, and sectors of your drive. The best strategy is to notch the settings back to "Auto." But the drive parameters put you squarely in geometry territory. TracksNo matter the type of magnetic media or style of head actuator used by a disk, the read/write head must stop its lateral motion across the disk whenever it reads or writes data. While it is stationary, the platter spins underneath it. Each time the platter completes one spin, the head traces a full circle across its surface. This circle is called a track. A disk drive stores the data-bits of a given track sequentially, as if it were a strip of tape spliced end to end. With every spin, the same data passes by the head, as long as the drive holds in the same place. The electronics of the drive select which portion of the track to read (or write) to find a random block of data. CylindersEach head traces out a separate track across its associated platter. The head actuator locks all the heads together so that all are at the same position from the center of the disk along a given radius. Because the combination of all the tracks traced out at a given head actuator position forms the skeleton of a solid cylinder, such a vertical stack of tracks is often termed exactly thata cylinder. The number of cylinders in a drive is the same as the number of tracks on a platter in that drive. Both numbers are permanently determined when the manufacturer makes the drive. In most drives, the number of cylinders is set by a magnetic pattern called a servo pattern. Older hard disks dedicated one surface of a platter to this servo information. Most modern disks put the servo information on the same surface as the stored data. The servo information gets read along with the data, and the drive electronics sort everything outusing the servo information to find its place and sending the data to your applications. This kind of hard disk is called an embedded servo drive. The more cylinders in the drive, the more data the drive can store. The maximum number of cylinders is limited by physical factors inherent in the technology used by the drive. More tracks on each platter means the tracks are squeezed closely together, forcing them to be smaller. The minimum width of a track is set by the size of the head but is limited by other factorssuch as how closely the head flies to the disk surfacethat also limit the amount of information that the drive can fit into each track. Once hard disk drives had as few as 312 cylinders. Modern drives have thousands. SectorsMost hard disk systems further divide each track into short arcs termed sectors, and the sector is the basic storage unit of the drive. Some operating systems use the sector as their basic storage unit, as does the NTFS system used by Windows NT and Windows 2000, for example. Under the VFAT system of Windows 95 and Windows 98, however, the operating system gathers together several sectors to make its basic unit of storage for disk filesthe cluster. Sectors can be soft, marked magnetically with bit-patterns embedded in the data on the track itself, or hard, set by the drive mechanism itself. Soft sectors are demarcated using a low-level format program, and their number can vary almost arbitrarily depending on the formatting software and the interface used for connecting the disk. Disks with device-level interfaces are essentially soft-sectored. For all practical purposes, disks with system-level interfaces are hard-sectored because their sector size is set by the servo information encoded on the drive platters, which cannot be changed once the drive leaves the factory. Magneto-optical cartridges are hard-sectored by an embedded optical format prerecorded on the medium. In the computer hard disk industry, the size of a sector is, by convention, almost universally 512 bytes. The number of sectors per track depends on the design of the disk. The sector count on any given track of older hard disks is the same as every other track because of their use of constant angular velocity recording. Most modern hard disk drives use a technique called multiple zone recording (MZR), which puts variable numbers of sectors on each track. MZR allows the drive-maker to use the storage capacity of the magnetic medium more efficiently. A disk with a fixed number of sectors per track stores data at lower densities in its outer tracks than it does in its inner tracks. Only the innermost tracks pack data at the highest density allowed by the medium. All the other tracks must be recorded at a lower density, an inevitable result of the constant angular velocity recording used by the hard disk and the fixed frequency of the data signals. Multiple zone recording allows the drive to maintain a nearly constant data density across the disk by dividing it into zones. The drive alters the frequency of the data signals to match each zone. Using higher frequencies in the zones near the outer tracks of a disk increases their data density to about that of the inner tracks. This, in turn, can substantially increase overall disk capacity without compromising reliability or altering the constant spin needed for quick access. Sometimes MZR technology is described as zoned constant angular velocity (ZCAV) recording, a term which confirms that the spin rate remains the same (constant angular velocity) but the platter is divided into areas with different recording densities (zones). Seagate Technologies uses a proprietary form of MZR called zone-bit recordingdifferent name, same effect. Physical FormatThe geometry of a disk drive describes only the numbers of the various drive parameterscylinders, heads, and sectors. The drive format describes the arrangement and alignment of these parameters. Disk geometry fixes the tracks as concentric circles, with the sectors as small arcs within each track. The format defines the location of the sectors in regard to one anotherthat is, the order in which they are read. Sectors need not be read one after another in a given track. Moreover, their starting edges need to exactly align on the disk. Neither tracks nor sectors are engraved on the surface of individual platters. They are instead defined magnetically by coded bit-patterns recorded on the disk. Before data can be written on such a disk, the sectors have to be marked to serve as guideposts markers so that the information can later be found and retrieved. The process by which sectors are defined on the hard disk is called low-level formatting because it occurs at a control level below the reaches of normal Windows commands. Three methods have found general application in defining tracks: simply by the count of the stepper motor in the oldest band-stepper drives, by the permanently recorded track servo data on the dedicated servo surface of old servo-voice coil drives, and by embedded servo data in modern drives. In classic hard disk drives, special bit-patterns on the disk serve as sector-identification markings. The patterns indicate the start of the sector and encode an ID number that gives the sector number within the track. The sector ID precedes each sector; error-correction data typically follows each sector. In normal operation, the disk servo system seeks a particular track, then the drive begins to read sector IDs until it finds the sector that your computer has requested. The sector ID can consume a significant portion of the available space on each disk track, about 10 percent. Consequently, manufacturers have sought means to eliminate it. For example, the No-ID Format developed by IBM eliminates sector IDs by putting a format map in RAM. The map tells the drive where on each track each sector is located and which sectors have been marked bad. The map, for example, tells the drive how many sectors are on a track in a zoned recording system and where each begins in reference to the track servo information embedded on the disk. This format also improves access speed because the drive can immediately locate a given sector without detours in chasing replacements for defective sectors. File SystemTo store a file on disk, the FAT file system breaks it down into a group of clusters, perhaps hundreds of them. Each cluster can be drawn from anywhere on the disk. Sequential pieces of a file do not necessarily have to be stored in clusters that are physically adjacent. The earliestand now obsoleteversions of the FAT file system followed a simple rule in picking which clusters are assigned to each file. The first available cluster, the one nearest the beginning of the disk, is always the next one used. Therefore, on a new disk, clusters are picked one after another, and all the clusters in a file are contiguous. When a file is erased, its clusters are freed for reuse. These newly freed clusters, being closer to the beginning of the disk, are the first ones chosen when the next file is written to disk. In effect, a FAT-based file system first fills in the holes left by the erased file. As a result, the clusters of new files may be scattered all over the disk. The earliest versions of the FAT file system used this strange strategy because they were written at a time when capacity was more important than speed. The goal was to pack files on the disk as stingily as possible. For more than a decade, however, the FAT system has used a different strategy. Instead of immediately trying to use the first available cluster closest to the beginning of the disk, the file system attempts to write on never-before-used clusters before filling in any erased clusters. This helps ensure that the clusters of a file are closer to one another, a technique that improves the speed of reading a file from the disk. File Allocation TableTo keep track of which cluster belongs in which file, the default file system of consumer Windows (including 95, 98, Me, and XP) uses a file allocation table (FAT), essentially a map of the clusters on the disk. When you read to a file, the FAT-based file system automatically and invisibly checks the FAT to find all the clusters of the file; when you write to the disk, it checks the FAT for available clusters. No matter how scattered over your disk the individual clusters of a file may be, youand your softwareonly see a single file. FAT-based file systems simply number all the clusters in a manner similar to the way a disk drive numbers logical blocks. The operating system keeps track of the cluster numbers and in what order clusters have been assigned to a given file. The operating system stores most of the cluster data in the file allocation table. The FAT file system works by chaining together clusters. The directory entry of a file or subdirectory contains several bytes of data in addition to the file's name. Along with the date the file was last changed and the file's attributes is the number of the first cluster used to store the file or subdirectory. When the operating system reads a file, it first checks the directory entry to find the first cluster number. In addition to reading the data from the cluster from the disk, the operating system also checks the file allocation table for the entry with the number corresponding to the first cluster number. This FAT entry indicates the number of the next cluster in the file. After reading that cluster, the operating system checks the entry corresponding to that cluster number to find the next cluster. If the file has no additional clusters, the cluster entry has a value of 0FF(hex). The operating system assigns unused clustersthose available for adding to files to store datathe value of zero. When the standard FAT-based computer operating system erases a file, it merely changes the first character of the filename in the directory entry to 0E5(hex) and changes all the FAT entries of the file to zero. Because the rest of the directory information remains intact (at least until the file system runs out of space for directory information and overwrites the entries of erased files), it can be recovered to help reconstruct accidentally erased files. An unerase or undelete utility checks the directory for entries with the first character of 0E5(hex) and displays what it finds as candidates for recovery. From the remaining directory data, the unerasing program can locate the first cluster of the file. Finding the remaining clusters from the FAT is a matter of making educated guesses. The FAT of a disk is so important that Windows guards against losing its data by putting two complete (and identical) copies of the FAT end to end on the disk. ClustersAs clever as using clusters to allocate file data may be, the technique has its drawback. It can be wasteful. Disk space is divvied up in units of a cluster. No matter how small a file (or a subdirectory, which is simply a special kind of file) may be, it occupies at minimum one cluster of disk space. Larger files take up entire clusters, but any fractional cluster of space that's left over requires another cluster. On average, each file on the disk wastes half a cluster of space. The more files, the more waste. The larger the clusters, the more waste. Unless you work exclusively with massive files, increasing cluster size to increase disk capacity is a technique to avoid whenever possible. The first versions of DOS used FATs with 12-bit entries for cluster numbers, which allowed a total of 4096 uniquely named clusters. Later, Microsoft updated the FAT to use 16-bit entries, and this FAT structure, usually called FAT16, was used through Windows 95. By that time, however, disks had become larger than a 16-bit structure could reasonably handle. Microsoft introduced a new 32-bit FAT with the second edition of Windows 95. The new system, commonly called FAT32, reserves 4 of its 32 bits for future purposes, so each cluster is actually identified with a 28-bit value. Using FAT32, recent Windows versions can accommodate drives up to 2048GB and on smaller disks store files more efficiently with smaller clusters (see Table 17.2).
FAT32 is the most recent version, and drivers for it ship with all current Windows versions. If you choose to use a FAT-based file system, Windows will ask if you want large disk support and automatically install FAT32. CompressionMicrosoft includes a disk-compression system with many Windows versions that the company calls DriveSpace. The file system takes uncompressed data one cluster at a time and maps it in compressed form into sectors in the compressed volume file. To locate which sector belongs to each file, the file system uses a special FAT called the Microsoft DoubleSpace FAT (or MDFAT, with DoubleSpace being the DriveSpace predecessor) that encodes the first sector used for storing a given cluster, the number of sectors required for coding the cluster, and the number of the cluster in the uncompressed volume that's stored in those sectors. When the operating system needs the data from a file, the file system first searches for the clusters in the main disk FAT and then looks up the corresponding starting and length values in the MDFAT. With that information, the operating system locates the data, uncompresses it, and passes it along to your applications. To speed up operations when writing compressed data to disk, the operating system uses a second kind of FAT in the compressed volume file. Called the BitFAT, this structure reports which sectors reserved in the compressed volume file hold active data and which are empty. The BitFAT uses only one bit for each sector as a flag to indicate whether a sector is occupied. New Technology File SystemWindows NT, Windows 2000, and Windows XP give you two choices for your file system: the same old FAT-based system used since time began and the newer Windows NT File System, usually termed NTFS. The centerpiece of the NTFS is the master file table (MFT), which stores all the data describing each directory and file on a given disk. The basic data about each file is contained in a file record in the master file table. These file records may be two, four, or eight sectors long (that is, 1KB, 2KB, or 4KB). The first 16 records are reserved for system use to hold data of special metadata files, the first of which stores the attributes of the master file table itself. To NTFS, a file is a collection of attributes, each of which describes some aspect of the file. One of the attributes is the name of the file, another is the data contained in the file. Others may include who worked on the file and when it was last modified. The master file table tracks these attributes. To identify attributes, the file system assigns each file a unique ID number, a 48-bit value (allowing for nearly 300 trillion entries). Instead of the clusters used by the FAT system, NTFS uses the sector as its basic unit of storage. Sectors on a disk or partition are identified by relative sector numbers, each of which is 32 bits longsufficient to encode 4,294,967,296 sectors or a total disk space of 2048GB. Sectors are numbered sequentially, starting with the first one in the partition. Files are allocated in multiples of single sectors; directories, however, are made from one or more blocks of four sectors. Each file or directory on the disk is identified by its File NODE, which stores descriptive data about the file or directory. This information includes file attributes, creation date, modification dates, access dates, sizes, and a pointer that indicates in which sector the data in the file is stored. Each File NODE is one sector (512 bytes) long. Up to 254 bytes of the File NODE of a disk file store an extended filename, which can include upper- and lowercase characters, some punctuation (for example, periods), and spaces. An NTFS disk organizes its storage from a root directory. In an NTFS system, however, the root directory does not have a fixed location or size. Instead, the root directory is identified by reference to the disk super block, which is a special sector that is always kept as the 16th sector from the beginning of the HPFS partition. The 12th and 13th bytesthat is, at an offset of 0C(hex) from the start of the blockof the super block point to the location of the root directory File NODE. Free space on the disk is identified by a bitmapped table. As with other FNODEs, a pointer in the root directory FNODE stores the location of the first block of four sectors assigned to the root directory. The root directory is identical to the other directories in the HPFS hierarchy, and like them it can expand or shrink as the number of files it contains changes. If the root directory needs to expand beyond its initial four sectors, it splits into a tree-like structure. The File NODE of the root directory then points to the base File NODE of the tree, and each pointer in the tree points to one directory entry and possibly a pointer to another directory node that may in turn point to entries whose names are sorted before the pointer entry. This structure provides a quick path for finding a particular entry, along with a simple method of scanning all entries. NTFS can accommodate any length file (that will fit in the partition, of course) by assigning multiple sectors to it. These sectors need not be contiguous. NTFS, however, preallocates sectors to a file at the time it is opened, so a file may be assigned sectors that do not contain active data. The File NODE of the file maintains an accurate total of the sectors that are actually used for storing information. This preallocation scheme helps prevent files from becoming fragmented. Normally, the block of sectors assigned to a file will be contiguous, and the file will not become fragmented until all the contiguous sectors have been used up. Two types of sectors are used to track the sectors assigned a given file. For files that have few fragments, the File NODE maintains a list of all the relative sector numbers of the first sector in a block of sectors used by the file, as well as the total number of sectors in the file before those of each block. To capture all the data in a file, the operating system finds the relative sector number of the first block of sectors used by the file and the total number of sectors in the block. It then checks the next relative sector number and keeps counting with a running total of sectors in the file. If a file has many fragments, it uses a tree-style table of pointers to indicate the location of each block of sectors. The entry in the file's File NODE table then stores pointers to the sectors, which themselves store pointers to the data. Each of these sectors identifies itself with a special flag, indicating whether it points to data or to more pointers. Besides its huge capacity, NTFS has significant advantages when dealing with large hierarchies of directories, directories containing large number of files, and large files. Although both the NTFS and FAT use tree-structured directory systems, the directories in the NTFS are not arranged like a tree. Each directory gets stored in a tree-like structure that, coupled with the presorting of entries automatically performed by the NTFS, allows for faster searches of large directories. NTFS also arranges directories on the disk to reduce the time required to access theminstead of starting at the edge of the disk, they fan out from the center. The master file table attempts to store all the attributes of a file in the record it associates with that file. When the attributes of a file grow too large to be held in the MFT record, the NTFS just spreads the attribute data across as many additional disk clusters' records to create as many nonresident attributes as are needed to hold the file. The master file table keeps track of all the records containing the attributes associated with a given file by the file's ID number. This system allows any file to grow as large as the complete storage space available while preserving a small allocation unit size. No matter how large a disk or partition is, NTFS never allocates space in increments larger than 4KB. Performance IssuesWhen shopping for hard disks, many people become preoccupied with disk performance. They believe that some drives find and transfer information faster than others. They're right. But the differences between state-of-the-art hard disk drives are much smaller than they used to be, and in a properly set-up system, the remaining differences can be almost completely equalized. The performance of a hard disk is directly related to design choices in making the mechanism. The head actuator has the greatest effect on the speed at which data can be retrieved from the disk, with the number of platters exerting a smaller effect. Because the head actuator designs used by hard diskmakers have converged, as have the number of platters per drive because of height restrictions of modern form factors, the performance of various products has also converged. Clearly, however, all hard disks don't deliver the same performance. The differences are particularly obvious when you compare a drive that's a few years old with a current product. Understanding the issues involved in hard disk performance will help you better appreciate the strides made by the industry in the last few years and show you what improvements may still lie ahead. Average Access TimeYou've already encountered the term latency, which indicates the average delay in finding a given bit of data imposed because of the spin of the disk. Another factor also influences how long elapses between the moment the disk drive receives a request to reveal what's stored at a given place on the disk and when the drive is actually ready to read or write at that placethe speed at which the read/write head can move radially from one cylinder to another. This speed is expressed in a number of ways, often as a seek time. Track-to-track seek time indicates the period required to move the head from one track to the next. More important, however, is the average access time (sometimes rendered as average seek time), which specifies how long it takes the read/write head to move on the average to any cylinder (or radial position). Lower average access times, expressed in milliseconds, are better. The type of head actuator technology, the mass of the actuator assembly, the physical power of the actuator itself, and the width of the data area on the disk all influence average access time. Smaller drives have some inherent advantages in minimizing average access time. Their smaller, lighter head and actuators have less inertia and can accelerate and settle down faster. More closely spaced tracks mean the head needs to travel a shorter distance in skipping between them when seeking data. Real-world access times vary by more than a factor of ten. The first computer-size hard disks had access times hardly better than floppy disks, sometimes as long as 150 milliseconds. The newest drives are usually below ten milliseconds; some are closer to six milliseconds. How low an average access time you need depends mostly on your impatience. Quicker is always better and typically more costly. You can feel the difference between a slow and fast drive when you use your computer, particularly when you don't have sufficient memory to hold all the applications you run simultaneously. Once access time is below about ten microseconds, however, you may be hard pressed to pay the price of improvement. Disk-makers have explored all sorts of exotic technologies to reduce access time. Some primeval hard disks had a dozen or more fixed heads scanning huge disks. Because the heads didn't move, the access time was close to zeromore correctly, half the latency of the drive. About a decade ago, drive-makers experimented with dual-actuator drivestwo heads mean less than half the waiting because with an intelligent controller the drive could overlap read and write requests. None of these technologies made it into the computer mainstream because an even better ideaone much simpler and cheaperhas taken the forefront: the disk array (discussed later). Instead of multiple actuators in a single drive, arrays spread the multiple actuators among several drives. Advanced disk controllers, particularly those used in disk arrays, are able to minimize the delays caused by head seeks using a technique called elevator seeking. When confronted with several read or write requests for different disk tracks, the controller organizes the requests in the way that moves the head the least between seeks. Like an elevator, it courses through the seek requests from the lower-numbered tracks to the higher-numbered tracks and then goes back on the next requests, first taking care of the higher-numbered tracks and working its way back to the lower-numbered tracks. The data gathered for each individual request is stored in the controller and doled out at the proper time. Data-Transfer RateOnce a byte or record is found on the disk, it must be transferred to the host computer. Another disk system specificationthe data-transfer ratereflects how fast bytes are batted back and forth, effecting how quickly information can shuttle between microprocessor and hard disk. The transfer rate of a disk is controlled by a number of design factors completely separate from those of the average access time. The transfer rate of a hard disk is expressed in megahertz (MHz) or megabytes per second (or MBps, which is one-eighth the megahertz rate). The figure is invariably the peak transfer rate, the quickest that a single byte can possibly move, at least in theory, when all conditions are the most favorable and there's a strong tailwind. In truth, information never moves at the peak transfer rateonly the signals containing the data switch at the peak rate. The actual flow of data is burdened by overhead of various sorts, both in the hardware interface and the software data exchange protocol. That said, although the actual number expressed in the peak transfer rate is purely bogus if you want to count how fast data moves, such numbers do allow you to compare interfaces. Transferring information in modern systems requires about the same overhead, notwithstanding the interface standard (although there are differences). Therefore, a disk that has a peak transfer rate of 320MBps is faster than one with a rate of 133MBps, regardless of how fast each can actually move bytes. In modern usage, the peak transfer rate is often reserved for discussions of disk interfaces. Disks themselves are constrained by their physical nature. How fast they can produce information is governed by how closely the information is linearly packed and how fast it moves under the read/write head. The faster it moves, the more data the head sees in a second. The biggest factor in determining this speed is the spin rate of the disk. A faster spinning disk reveals more flux transitions to the read/write head. As a result, today most people focus on the spin rate of the disk to measure its data-transfer performance. Disk CachingThe ultimate means of isolating your computer from the mechanical vagaries of hard disk seeking is disk caching. Caching eliminates the delays involved in seeking when a read request (or write request in a system that supports write caching) involves data already stored in the cachethe information is retrieved at RAM speed. Similarly, the cache pushes the transfer rate of data stored in the cache up to the ceiling imposed by the slowest interface between the cache and host microprocessor. With an on-disk cache, the drive interface will likely be the primary constraint; with a hardware cache in the disk controller or host adapter, the bus interface is the limit; with a software cache, microprocessor and memory-access speed are the only constraints. AV DrivesDrive-makers have tailored a special breed of hard disk to suit the needs of audio and video recording and editing. Called AV drives because their primary application is audio and video, these drives are optimized for transferring large blocks of data sequentially (unlike normal hard disks, which must provide instant access to completely random data). Audio and video files tend to be long and linear and therefore read sequentially for long periods. Fast access time is not as important for such applications as is a high sustained data-transfer rate. For example, most video production today requires data rates of 27MBps but uses compression ratios averaging about ten to one to produce a data stream of about 2.7MBps that needs to be stored and retrieved. Most modern hard disks can achieve the performance required by audio and video applications, but hard diskmakers still offer a number of drives specially tailored to AV use. To achieve the highest possible performance, these AV drives add extensive buffering and may sacrifice or delay some data-integrity features. For example, they trade off absolute data security to eliminate interruptions in the high-speed flow of information. The hard disk industry rationale for this design is that video data, unlike spreadsheets or databases, tolerates errors well, so a short sequence of bad data won't hurt anything. After all, a single sector isn't even a third of a line of uncompressed video. The video subsystem can correct for such one-time errors in part of a line, masking them entirely. One way to prevent interruptions in the flow of data is to alter error handling. Engineers usually require that most hard disk drives attempt to reread the disk when they encounter an error. Most manufacturers use elaborate algorithms to govern these rereads, often minutely changing the head position or performing an entire thermal calibration. If these are not successful, the drive may invoke its error-correction code to reconstruct the data. AV drives alter these priorities. Because error correction is entirely electronic and imposes no mechanical delays, AV drives use it first to attempt error recovery. Only after error correction fails may the drive try to reread the data, often for a limited number of retries. Advanced hard disks log the errors that they encounter so that they may be used later for diagnostics. The logging operation itself takes time and slows disk performance. AV drives delay error logging until it does not interrupt the data stream. One feature that slows down conventional drives is sector remapping, which AV drives avoid to sidestep its performance penalties. The remapping process imposes delays on the flow of data because the read/write head of the drive must jump from one place to another to write or retrieve the data from the remapped sector at the time of the data access. AV drives often avoid auto-relocation to prevent interruption of the flow of high-speed data. Drive ArraysWhen you need more capacity than a single hard disk can provide, you have two choices: Trim your needs or plug in more disks. But changing your needs means changing your lifestyleforegoing instant access to all your files by deleting some from your disk, switching to data compression, or keeping a tighter watch on backup files and intermediary versions of projects under development. Of course, changing your lifestyle is about as easy as teaching an old dog to change its spots. The one application with storage needs likely to exceed the capacity of today's individual hard disks200GB and climbingis a network server, and a total lifestyle change for a network server is about as probable as getting a platoon of toddlers to clean up a playroom littered with a near-infinite collection of toys. Consequently, when the bytes run really low, you're left with the need for multiple disks. In most single-user computers, each of these multiple drives acts independently and appears as a separate drive letter (or group of drive letters) under common Windows. Through software, such multiple-drive systems can even be made to emulate one large disk with a total storage capacity equal to that of its constituent drives. Because Windows 95 and Windows 98 handle I/O seriallythey can do only one I/O task at a timesuch a solution is satisfactory, but it's hardly the optimum arrangement where reliability and providing dozens of users instant access is concerned. Instead of operating each disk independently, you can gain higher speeds, greater resistance to errors, and improved reliability by linking the drives through hardware to make a drive arraywhat has come to be known as a Redundant Array of Inexpensive Disks, or RAID. PrinciplesThe premise of the drive array is elementarycombine a number of individual hard disks to create a massive virtual system. But a drive array is more than several hard disks connected to a single controller. In an array, the drives are coordinated, and the controller specially allocates information between them using a program called Array Management Software (AMS). The AMS controls all the physical hard disks in the array and makes them appear to your computer as if they were one logical drive. For example, in some drive arrays, the AMS ensures that the spin of each drive is synchronized and divides up blocks of data to spread among several physical hard disks. The obvious benefit of the drive array is the same as any multiple-disk installationcapacity. Two disks can hold more than one, and four more than two. But drive array technology can also accelerate mass-storage performance and increase reliability. Data StripingThe secret to both of these innovations is the way the various hard disks in the drive array are combined. They are not arranged in a serial list, where the second drive takes over once the capacity of the first is completely used up. Instead, data is split between drives at the bit, byte, or block level. For example, in a four-drive system, two bits of every byte might come from the first hard disk, the next two bits from the second drive, and so on. The four drives could then pour a single byte into the data stream four times fastermoving all the information in the byte would only take as long as it would for a single drive to move two bits. Alternatively, a four-byte storage cluster could be made from a sector from each of the four drives. This technique of splitting data between several drives is called data striping. At this primitive level, data striping has a severe disadvantage: The failure of any drive in the system results in the complete failure of the entire system. The reliability of the entire array can be no greater than that of the least reliable drive in the array. The speed and capacity of such a system are greater but so are the risks involved in using it. Redundancy and ReliabilityBy sacrificing part of its potential capacity, an array of drives can yield a more reliable, even fault-tolerant, storage system. The key is redundancy. Instead of a straight division of the bits, bytes, and blocks each drive in the array stores, the information split between the drives can overlap. For example, in the four-drive system, instead of each drive getting two bits of each byte, each drive might store four. The first drive would take the first four bits of a given byte, the second drive the third, fourth, fifth, and sixth bits; the third drive, the fifth, sixth, seventh, and eighth bits; and the fourth drive, the seventh, eighth, first, and second bits. This digital overlap allows the correct information to be pulled from another drive when one encounters an error. Better yet, if any single hard disk should fail, all the data it stored could be reconstituted from the other drives. This kind of system is said to be fault tolerant. That is, a single faultthe failure of one hard diskwill be tolerated, meaning the system operates without the loss of any vital function. Fault tolerance is extremely valuable in network applications because the crash of a single hard disk does not bring down the network. A massive equipment failure therefore becomes a bother rather than a disaster. The sample array represents the most primitive of drive array implementations, one that is particularly wasteful of the available storage resources. Advanced information-coding methods allow for higher efficiencies in storage, so a strict duplication of every bit is not required. Moreover, advanced drive arrays even allow hot-swapping, a feature that permits a failed drive to be replaced and the data that was stored upon it reconstructed without interrupting the normal operation of the array. A network server with such a drive array need not shut down even for disk repairs. ImplementationsIn 1988, three researchers at the University of California at BerkeleyDavid A. Patterson, Garth Gibson, and Randy H. Katzfirst outlined five disk array models in a paper titled A Case for Redundant Arrays of Inexpensive Disks. They called their models RAID Levels and labeled them as RAID 1 through 5, appropriately enough. Their numerical designations were arbitrary and were not meant to indicate that RAID 1 is better or worse than RAID 5. The numbers simply provide a label for each technology that can be readily understood by the cognoscenti. In 1993, these levels were formalized in the first edition of the RAIDBook, published by the RAID Advisory Board, an association of suppliers and consumers of RAID-related mass storage products. The book is part of one of the RAID Advisory Board's principle objectivesthe standardization of the terminology of RAID-related technology. Although the board does not officially set standards, it does prepare them for submission to the recognized standards organizations. The board also tests the function and performance of RAID products and verifies that they perform a basic set of functions correctly. The RAID Advisory Board currently recognizes nine RAID implementation levels. Five of these conform to the original Berkeley RAID definitions. Beyond the five array levels described by the Berkeley group, several other RAID terms are used and acknowledged by the RAID Advisory Board. These include RAID Level 0, RAID Level 6, RAID Level 10, and RAID Level 53. The classification system is nonhierarchicala higher number does not imply a better or more advanced technology. The numbers are no more than labels for quickly identifying the technologies used. Because the common perceptionreally a misperceptionis that the numbers do imply a ranking and that higher is better, some manufacturers have developed proprietary labels (RAID 7) or exploited non-Berkeley definitions (RAID 10 and 53) with high numbers that hint they are somewhat better than the lower-numbered systems. Although each level has its unique advantages (and disadvantages), no one RAID technology is better than any of the others for all applications. In an attempt to avoid such confusion, the RAID Advisory Board now classifies disk array products by what they accomplish in protecting data rather than by number alone. The board's Web site includes both a description and listing of classified products. RAID Level 0Early workers used the term RAID Level 0 to refer to the absence of any array technology. According to the RAID Advisory Board, however, the term refers to an array that simply uses data striping to distribute data across several physical disks. Although RAID Level 0 offers no greater reliability than the worst of the physical drives making up the array, it can improve the performance of the overall storage system. For example, reading data in parallel from two drives can effectively double throughput. RAID Level 1The simplest of drive arrays, RAID Level 1, consists of two equal-capacity disks that mirror one another. One disk duplicates all the files of the other, essentially serving as a backup copy. Should one of the drives fail, the other can serve in its stead. This reliability is the chief advantage of RAID Level 1 technology. The entire system has the same capacity as one of its drives alone. In other words, the RAID Level 1 system yields only 50 percent of its potential storage capacity, making it the most expensive array implementation. Performance depends on the sophistication of the array controller. Simple systems deliver exactly the performance of one of the drives in the array. A more sophisticated controller could potentially double data throughput by simultaneously reading alternate sectors from both drives. Upon the failure of one of the drives, performance reverts to that of a single drive, but no information (and no network time) is lost. RAID Level 2The next step up in array sophistication is RAID Level 2, which interleaves bits or blocks of data as explained earlier in the description of drive arrays. The individual drives in the array operate in parallel, typically with their spindles synchronized. To improve reliability, RAID Level 2 systems use redundant disks to correct single-bit errors and detect double-bit errors. The number of extra disks needed depends on the error-correction algorithm used. For example, an array of eight data drives may use three error-correction drives. High-end arrays with 32 data drives may use seven error-correction drives. The data, complete with error-detection code, is delivered directly to the array controller. The controller can instantly recognize and correct for errors as they occur, without slowing the speed at which information is read and transferred to the host computer. The RAID Level 2 design anticipates that disk errors occur often, almost regularly. At one time, mass storage devices might have been error prone, but no longer. Consequently, RAID Level 2 can be overkill except in the most critical of circumstances. The principal benefit of RAID Level 2 is performance. Because of their pure parallel nature, RAID Levels 2 and 3 are the best-performing array technologies, at least in systems that require a single, high-speed stream of data. In other words, RAID Level 2 yields a high data-transfer rate. Depending on the number of drives in the array, an entire byte or even a 32-bit double-word could be read in the same period it would take a single drive to read one bit. Normal single-bit disk errors don't hinder this performance in any way because of RAID Level 2's on-the-fly error correction. The primary defect in the RAID Level 2 design arises from its basic storage unit being multiple sectors. As with any hard disk, the smallest unit each drive in the array can store is one sector. File sizes must increase in units of multiple sectorsone drawn from each drive. In a ten-drive array, for example, even the tiniest two-byte file would steal ten sectors (5120 bytes) of disk space. (Under the Windows VFAT system, which uses clusters of four sectors, the two-byte file would take a total of 20,480 bytes!) In actual applications this drawback is not severe because systems that need the single-stream speed and instant error correction of RAID Level 2 also tend to be those using large files (for example, mainframes). RAID Level 3This level is one step down from RAID Level 2. Although RAID Level 3 still uses multiple drives operating in parallel, interleaving bits or blocks of data, instead of full error correction it allows only for parity checking. That is, errors can be detected but without the guarantee of recovery. Parity checking requires fewer extra drives in the arraytypically only one per arraymaking it a less expensive alternative. When a parity error is detected, the RAID Level 3 controller reads the entire array again to get it right. This rereading imposes a substantial performance penaltythe disks must spin entirely around again, yielding a 17 millisecond delay in reading the data. Of course, the delay appears only when disk errors are detected. Modern hard disks offer such high reliability that the delays are rare. In effect, RAID Level 3 compared to RAID Level 2 trades off fewer drives for a slight performance penalty that occurs only rarely. RAID Level 4This level interleaves not bits or blocks but sectors. The sectors are read serially, as if the drives in the array were functionally one large drive with more heads and platters. (Of course, for higher performance, a controller with adequate buffering could read two or more sectors at the same time, storing the later sectors in fast RAM and delivering them immediately after the preceding sectors have been sent to the computer host.) For reliability, one drive in the array is dedicated to parity checking. RAID Level 4 earns favor because it permits small arrays of as few as two drives, although larger arrays make more efficient use of the available disk storage. The dedicated parity drive is the biggest weakness of the RAID Level 4 scheme. In writing, RAID Level 4 maintains the parity drive by reading the data drives, updating the parity information, and then writing the update to the parity drive. This read-update-write cycle adds a performance penalty to every write, although read operations are unhindered. RAID Level 4 offers an extra benefit for operating systems that can process multiple data requests simultaneously. An intelligent RAID Level 4 controller can process multiple input/output requests, reorganize them, and read its drives in the most efficient manner, perhaps even in parallel. For example, while a sector from one file is being read from one drive, a sector from another file can read from another drive. This parallel operation can improve the effective throughput of such operating systems. RAID Level 5This level eliminates the dedicated parity drive from the RAID Level 4 array and allows the parity-check function to rotate through the various drives in the array. Error checking is thus distributed across all disks in the array. In properly designed implementations, enough redundancy can be built in to make the system fault tolerant. RAID Level 5 is probably the most popular drive array technology currently in use because it works with almost any number of drives, including arrays as small as two, yet permits redundancy and fault tolerance to be built in. RAID Level 6To further improve the fault tolerance of RAID Level 5, the same Berkeley researchers who developed the initial five RAID levels proposed one more, now known as RAID Level 6. This level adds a second parity drive to the RAID Level 5 array. The chief benefit is that any two drives in the array can fail without the loss of data. This enables an array to remain in active service while an individual physical drive is being repaired, yet still remain fault tolerant. In effect, a RAID Level 6 array with a single failed physical disk becomes a RAID Level 5 array. The drawback of the RAID Level 6 design is that it requires two parity blocks to be written during every write operation. Its write performance is extremely low, although read performance can achieve levels on par with RAID Level 5. RAID Level 10Some arrays employ multiple RAID technologies. RAID Level 10 represents a layering of RAID Levels 0 and 1 to combine the benefits of each. (Sometimes RAID Level 10 is called RAID Level 0&1 to more specifically point at its origins.) To improve input/output performance, RAID Level 10 employs data striping, splitting data blocks between multiple drives. Moreover, the Array Management Software can further speed read operations by filling multiple operations simultaneously from the two mirrored arrays (at times when both halves of the mirror are functional, of course). To improve reliability, the RAID level uses mirroring so that the striped arrays are exactly duplicated. This technology achieves the benefits of both of its individual layers. Its chief drawback is cost. As with simple mirroring it doubles the amount of physical storage needed for a given amount of logical storage. RAID Level 53This level represents a layering of RAID Level 0 and RAID Level 3the incoming data is striped between two RAID Level 3 arrays. The capacity of the RAID Level 53 array is the total of the capacity of the individual underlying RAID Level 3 arrays. Input/output performance is enhanced by the striping between multiple arrays. Throughput is improved by the underlying RAID Level 3 arrays. Because the simple striping of the top RAID Level 0 layer adds no redundant data, reliability falls. RAID Level 3 arrays, however, are inherently so fault tolerant that the overall reliability of the RAID Level 53 array far exceeds that of an individual hard disk drive. As with a RAID Level 3 array, the failure of a single drive will not adversely affect data integrity. Which implementation is best depends on what you most want to achieve with a drive array: Efficient use of drive capacity, fewest number of drives, greatest reliability, or quickest performance. For example, RAID 1 provides the greatest redundancy (thus reliability), and RAID 2 the best performance (followed closely by RAID 3). Parallel Access ArraysIn parallel access arrays, all the individual physical drives in the array participate in every input and output operation of the array. In other words, all the drives operate in unison. Systems that correspond to the RAID Level 2 or 3 design fit this definition. The drives in independent access arrays can operate independently. In advanced arrays, several individual drives may perform different input and output operations simultaneously, filling multiple input and output requests at the same time. Systems that follow the RAID Level 4 or 5 design fit this definition. Although RAID Level 1 drives may operate either as parallel access or independent access arrays, most practical systems operate RAID Level 1 drives independently. InterfacingJust connecting four drives to a SCSI controller won't create a drive array. An array requires special electronics to handle the digital coding and control of the individual drives. Usually these special electronics take the form of a RAID controller. The controller may be part of a standalone disk array in its own cabinet, in which case the array attaches to the host computer as a single SCSI device. Alternatively, the RAID controller may be a single expansion board that resembles a host adapter for a SCSI or AT Attachment interface but incorporates RAID electronics and usually megabytes of cache or buffer memory. The disk drives for the array may be installed inside the computer host or in a separate chassis. Most disk arrays use SCSI hard disks because that interface allows multiple drives to share a single connection. A growing number of manufacturers now offer AT Attachment (IDE) array controllers, which allow you to take advantage of lower cost ATA hard disks. The earliest of these supported only the four drives normally allowed in a single computer system under the ATA specifications. These typically allow you your choice of a RAID Level 0 or RAID Level 1 configuration. At least one manufacturer now offers a RAID Level 5 controller for ATA hard disk drives. |
| [ Team LiB ] |
|